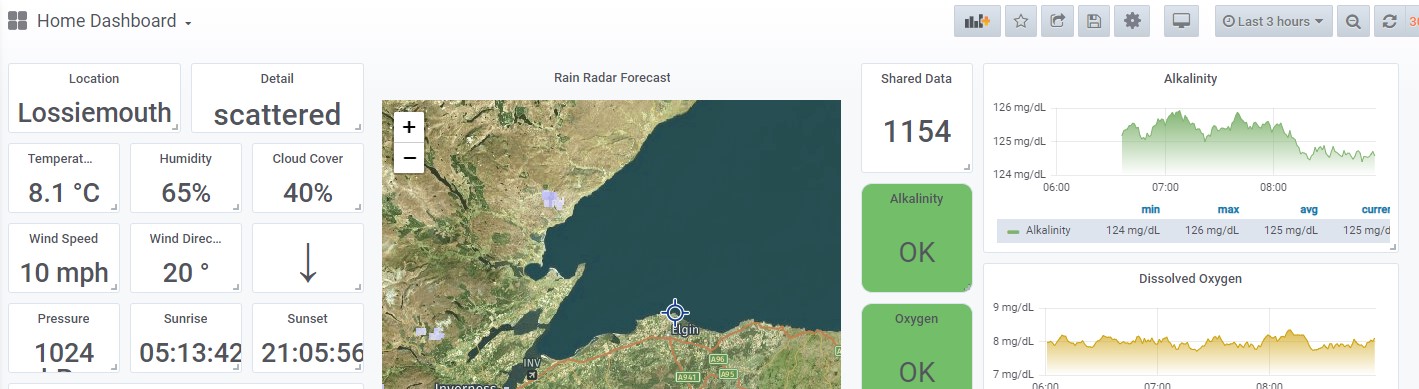
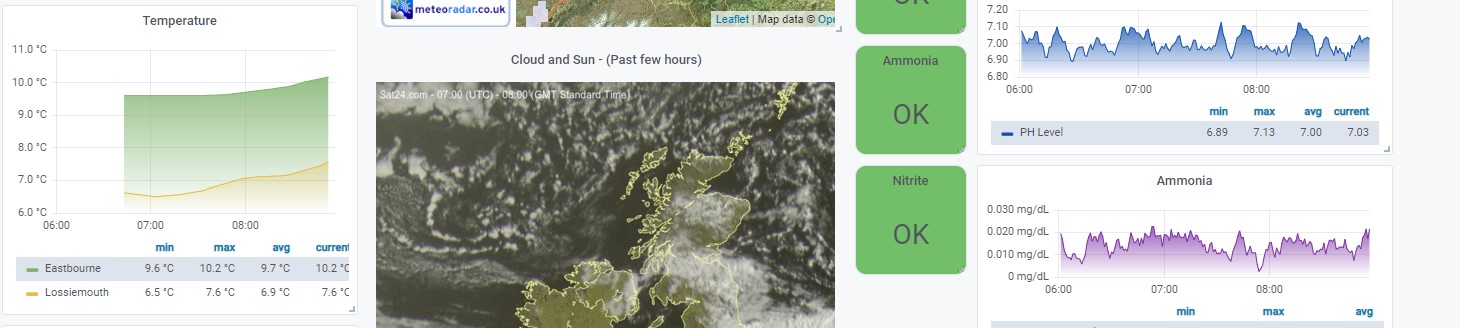
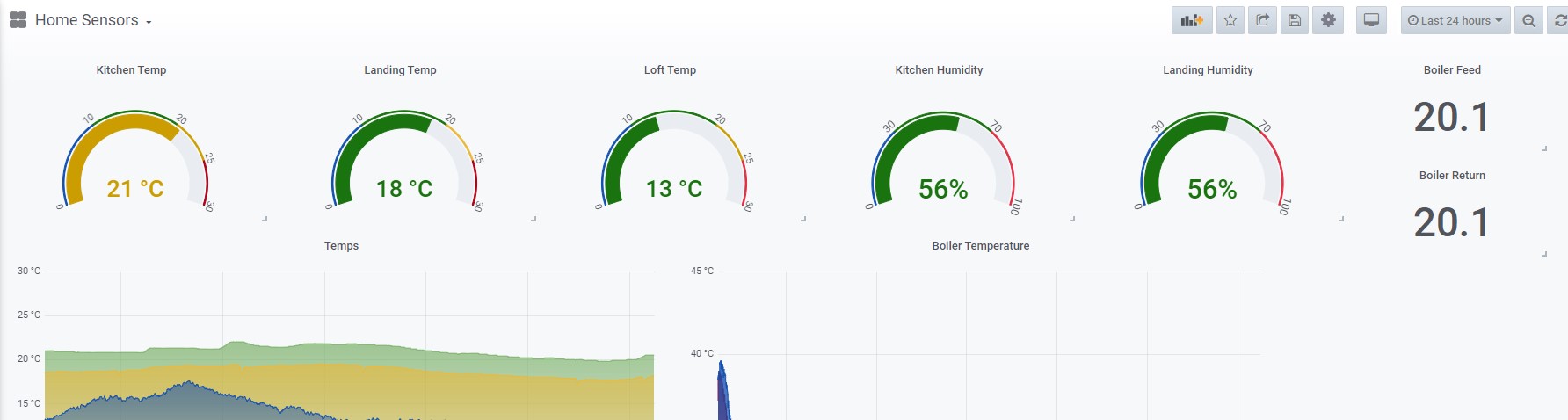

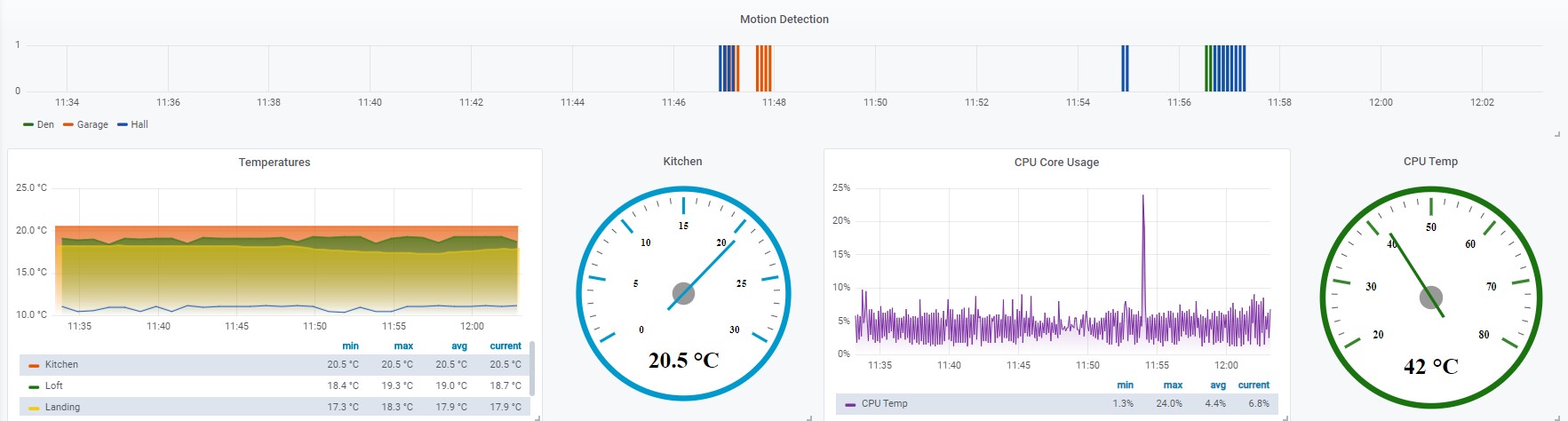

Characteristics of Time Series Data
Due to its distinct characteristics (listed below), time-series data is typically inefficient when managed with other databases:
- High-speed data ingest: Whether it is an IoT use case or market analysis data, you have a steady stream of data that arrives at high speeds and often in bursts. For most solutions, the data arrives 24/7, 365 days a year.
- Immutable data: Once inserted in the database, a data point does not undergo any changes until it is expired or deleted. The data is typically log data with a timestamp and a few data points.
- Unstructured labels: Time-series data is generally produced continuously over a long period of time by many sources. For example, in an IoT use case, every sensor is a source of time-series data. In such situations, each data point in the series stores the source information and other sensor measurements as labels. Data labels from every source may not conform to the same structure or order.
- Diminishing value over time: Only an aggregated summary of data with an appropriate time range would be relevant in the future. For example, in a year from now, most users will not require every data point stored at the range of milliseconds. Only aggregated and generalized data by a minute, hour or day would make sense in that case.
- Queries are aggregated by time intervals: Charts based on time-series data enable you to zoom in and out. They do so by aggregating their data by time intervals. Typically, time-series data queries are aggregations. This is in contrast to retrieving individual records from the database.
Problems with using traditional databases for time-series use cases
Many solutions still store time-series data in a relational database. This approach has many drawbacks, because relational databases:
- Are designed and optimized for transactional use cases.
- Carry the overhead of locking and synchronization that are not required for the immutable time-series data. This results in slower-than-required performance for both ingest and queries. Enterprises then end up investing in additional compute resources to scale out.
- Enforce a rigid structure for labels and cannot accommodate unstructured data.
- Require scheduled jobs for cleaning up old data.
- Are used for multiple use cases.
- Overuse of running time-series queries may affect other workloads.